.png)
We Benchmarked 7 ASR Models on Real Audio. Here's What We Found.
April 21, 2026

At SpeechLab, we process thousands of hours of audio every week across 25+ languages. Our dubbing pipeline depends on accurate transcription, and we don't take model selection on faith. We benchmark ASR models periodically against real production audio to decide what runs in our pipeline.
This round, we evaluated seven models — three open-source, two commercial APIs, and two newer entrants — on two English-language datasets: 21 short-form videos (2 hours) covering news, documentaries, and interviews, and 12 full-length podcast episodes (7.6 hours). We measured what matters for production: word error rate (WER), missed speech, chunk drops, and cost.
Here's what we found.
How We Tested: Real Audio, No Tuning, No Cherry-Picking
We ran every model with default parameters. No tuning, no prompt engineering, no cherry-picking favorable samples. The ground truth is human-edited transcripts — the same quality standard we use in production.
Datasets:
- Short-form: 21 videos (2 hours total) — news segments, interviews, documentaries. 1–12 minutes each, 1–5+ speakers, varying background noise levels.
- Long-form: 12 podcast episodes (7.6 hours total) — iHeart Media production podcasts. 5–58 minutes each, ranging from single-speaker to multi-narrator shows with heavy background music.
Metrics:
- WER (Word Error Rate): The standard measure of transcription accuracy.
- Missed speech: Total duration of audio where the reference has speech but the model produced nothing — a critical metric for dubbing, where a gap means silence in the final output.
- Chunk drops: Consecutive words the model deleted in a single run. A 5-word gap is recoverable. A 70-word gap is not.
- Cost per hour: For commercial APIs, at published rates.
All models are multilingual, but we only benchmarked English here — it's our highest-volume production language.
A note on alignment: No external forced alignment was applied to local models, with one exception — Qwen3-ASR uses its own built-in forced aligner (Qwen3-ForcedAligner-0.6B) to produce word timestamps so we could derive segment-level boundaries. IBM Granite does not output segment boundaries at all, so we ran Silero VAD as a pre-pass to supply them.
The Models

Which ASR Model Is Most Accurate?
On short-form content, WhisperX, AssemblyAI, and ElevenLabs are effectively tied — only 0.38 percentage points separate them:
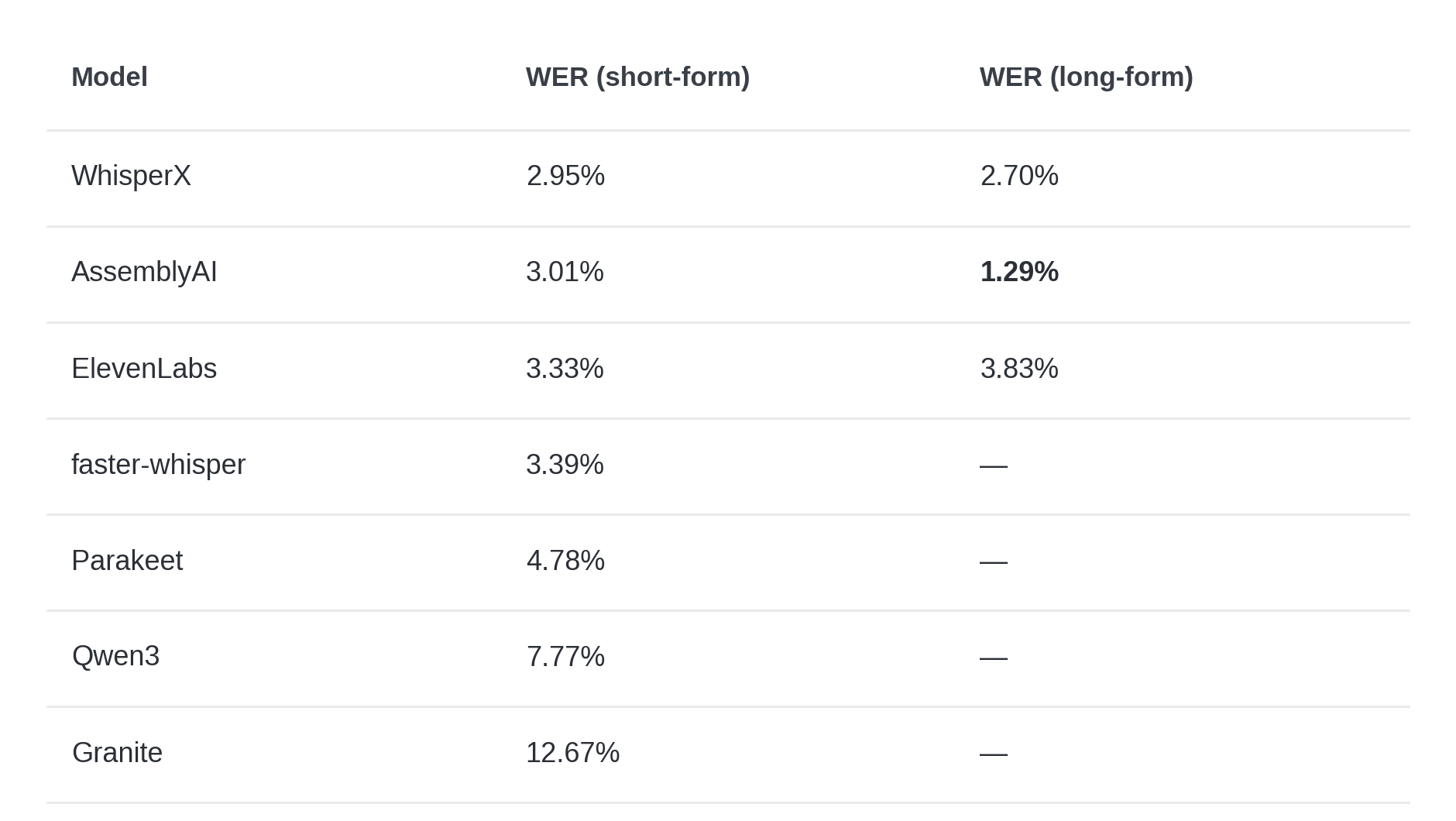
The standout result: AssemblyAI drops to 1.29% WER on long-form podcasts — the lowest we've measured on any model. Its accuracy more than doubles when processing 30–60 minute episodes, likely because the model benefits from longer context for language modeling.
ElevenLabs goes the other direction. On long-form content, its insertion rate climbs — it hallucinates filler words and repetitions — pushing WER up to 3.83%. It still deletes fewer words than any other model, but the over-transcription is a problem at scale.
Parakeet, Qwen3, and Granite are not competitive for English transcription. Parakeet (4.78% WER) is roughly 60% worse than the top three. Qwen3 (7.77%) and Granite (12.67%) are in a different league entirely. Granite covers the audio — it produces output for nearly every passage — but that output is often wrong.
Which Model Drops the Fewest Words?
In a dubbing pipeline, a dropped word creates a gap. A dropped sentence creates silence. We track "chunk drops" — runs of 5+ consecutive deleted words — because these are the failures that break the pipeline.

Short-form dataset (2 hours).
ElevenLabs and AssemblyAI are in a different class. Their worst drops are 9 words — a sentence fragment. Every local model has drops of 21–136 words. Granite's worst drop — 136 consecutive words, 47 seconds of audio — means an entire segment vanished.
On the 7.6-hour long-form dataset, ElevenLabs dropped only 2 chunks of 5+ words across all 12 episodes. AssemblyAI: 5. WhisperX: 14. The commercial APIs have proprietary post-processing that catches and repairs chunk drops before they reach the output. Open-source models don't.
This is the strongest argument for using a commercial API in a production pipeline: not accuracy, but reliability. When the model fails, you need the failure to be small.
How Much Speech Does Each Model Miss?
Missed speech — audio where the ground truth has words but the model produced nothing — is the metric that matters most for dubbing. A gap means silence where there should be a voice.
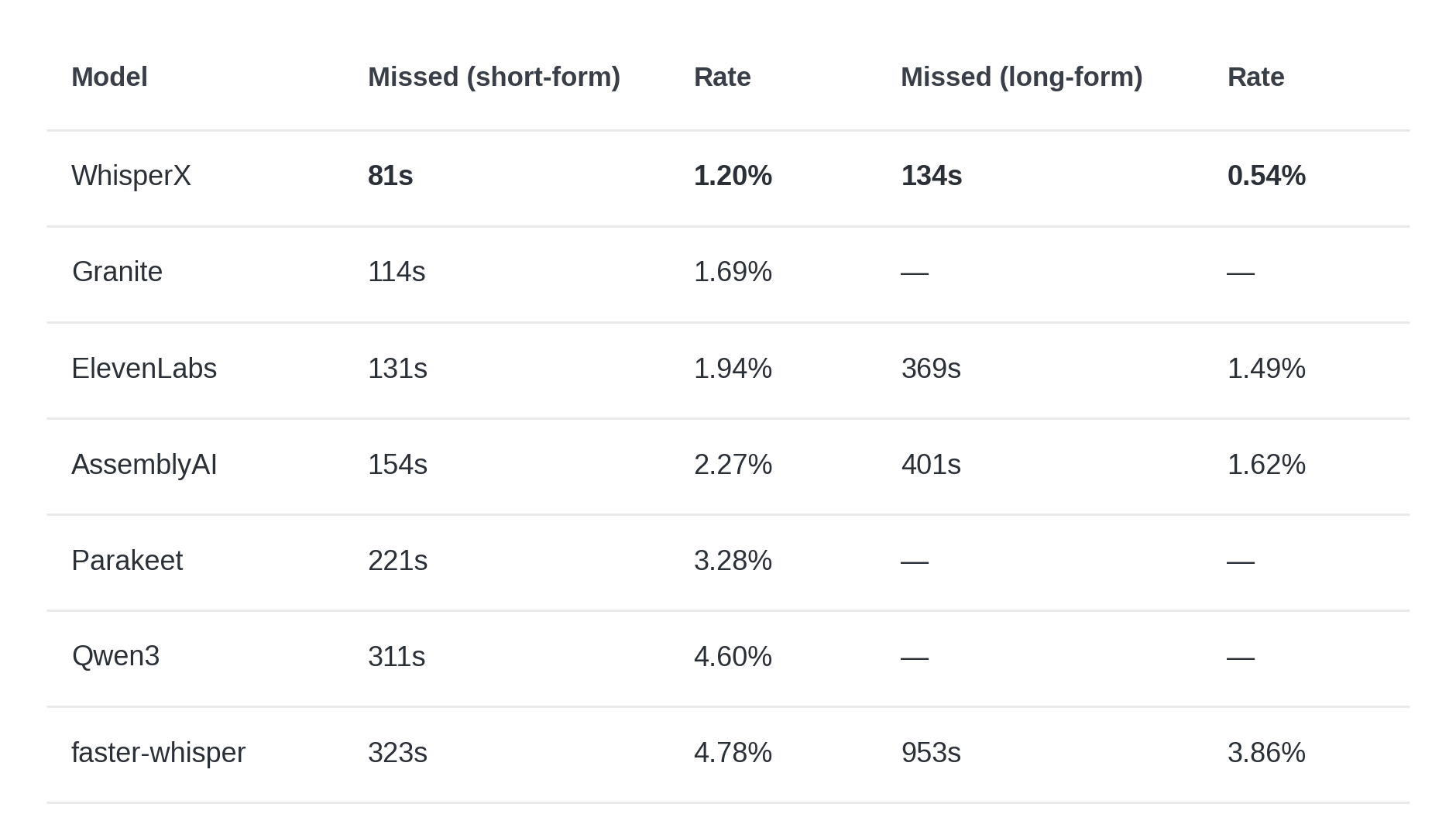
WhisperX misses the least speech of any model, and its advantage grows on longer content. On 7.6 hours of podcasts, it misses just 134 seconds (0.54%). The commercial APIs miss 2.7–3x more.
The surprise here: the API models' missed speech comes from many small boundary misalignments, not from catastrophic drops. They "nibble" at segment edges rather than dropping entire passages. WhisperX's chunked local processing handles long files naturally, while the API models may hit context-window or batching limitations on 30–60 minute episodes.
Granite's low missed-speech number (114s) is misleading — it covers the audio, but with 12.67% WER, much of what it produces is wrong.
How Does Cost Compare to Accuracy?
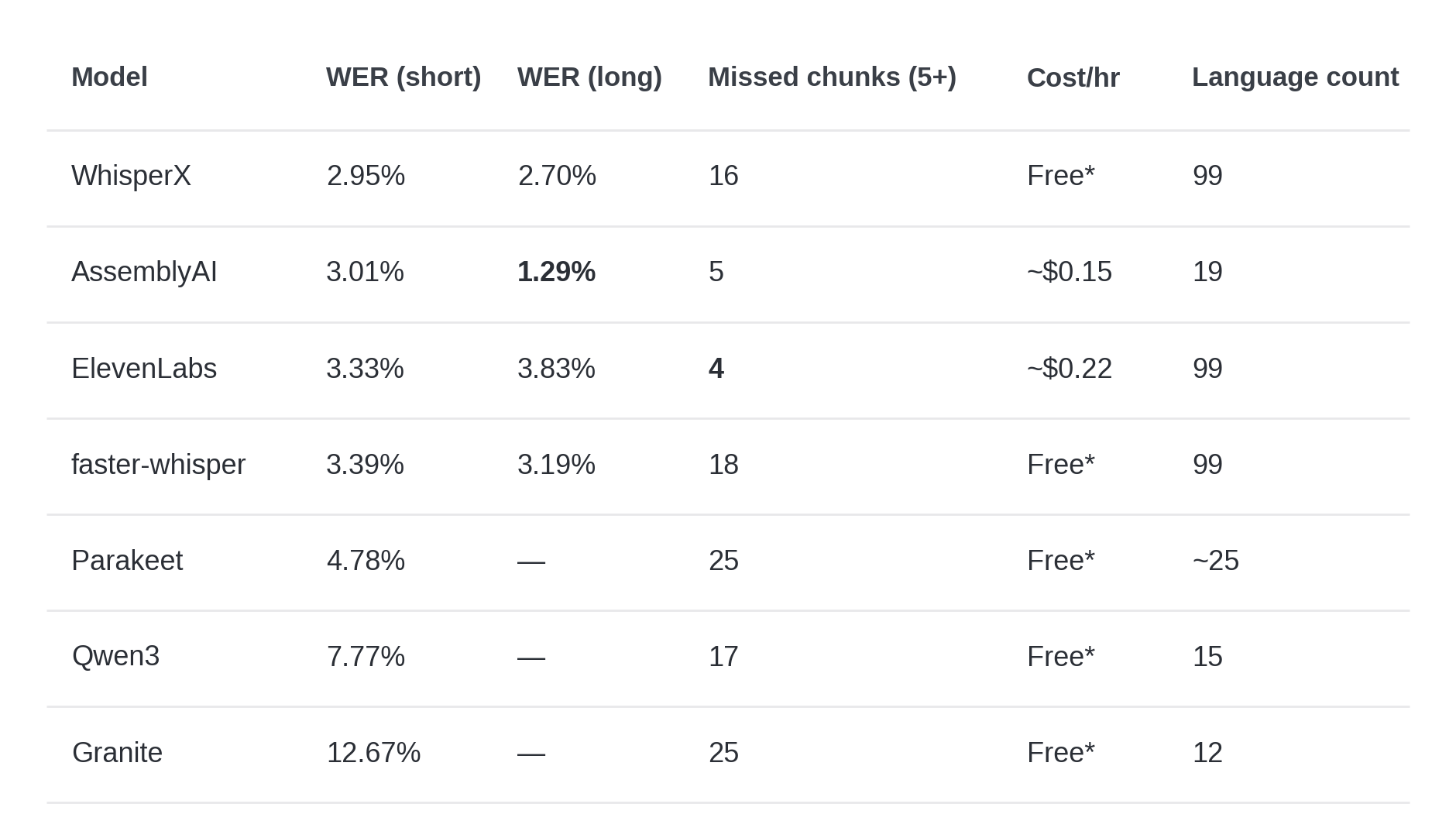
Requires GPU. WhisperX runs on a single consumer GPU (250 MB VRAM). Qwen3 needs 7.4 GB. Granite needs 4.6 GB.
At equivalent accuracy, AssemblyAI is 47% cheaper than ElevenLabs ($0.15/hr vs $0.22/hr). On long-form content, AssemblyAI is also significantly more accurate (1.29% vs 3.83% WER). ElevenLabs' edge is chunk-drop resilience: if you need to guarantee that no large passage goes missing, it's the safer bet.
WhisperX is free and matches or beats both APIs on coverage. But it has 3–4x more chunk drops, and its segment boundaries are not suitable for dubbing alignment without additional processing.
What We Run in Production
Our current production pipeline combines models. No single model wins across all dimensions — accuracy, coverage, chunk reliability, and segment timing all require different strengths.
We use a variation of Whisper as our primary model as it has the best combination of accuracy and language support, and anecdotally we find that it handles nuance of long-form spoken dialogue better than some of the API models. To fill the gap of dropped segments, we use a second commercial ASR model and a form of forced alignment to ensure full coverage.
The boundary problem remains unsolved. Segment timing — where each sentence starts and ends in the audio — is critical for dubbing. None of the models we tested produce boundaries precise enough for direct TTS alignment. As a result, we use our own forced alignment model to address this, and it's an active area of development for us and will be a focus of future benchmarks.
What's Next
We'll re-run these benchmarks as models improve. ASR is moving fast — models that underperformed this round may leapfrog the leaders in six months.
We did use data from multiple languages in our evaluation and will continue to focus on multilingual evaluation. English is our primary source language, but we support over 25 languages and dialects and will continue to add more. This calls for different strategies. For example, WhisperX's alignment depends on wav2vec models that vary dramatically in quality across languages — some trained on as little as 10 hours of data. We do not rely on WhisperX for alignment.
We'll publish those results when we have them. Follow us for future comparisons.
SpeechLab provides AI-powered dubbing and localization for enterprise media. We process audio at scale across 25+ languages for clients including iHeart Media. Learn more at speechlab.ai.
.png)